

Koffie zetten met de MAX78000 en een stukje AI
op
Met moderne hardware kunnen we het gebruik van convolutionele neurale netwerken (CNN’s) versnellen. CNN’s worden veel gebruikt voor de analyse van beelden en geluiden. Dat opent nieuwe mogelijkheden om data te verwerken en interactie aan te gaan met de omgeving. Voor het werken met een CNN is veel rekenkracht nodig. Voor een CPU is dat meestal teveel, daarom wordt een versneller gebruikt. Op een PC kan dat door hulp in te roepen van de grafische kaart of van een aparte accelerator zoals de Tesla-kaarten van NVIDIA (soms is zo’n accelerator al ingebouwd in het systeem zelf, zoals bij de nieuwe Apple M1-processor). De MAX78000 van Maxim Integrated bevat (volgens het datasheet) een CNN-accelerator, een Cortex-M4F en een RISC V-kern. De kaart is geschikt om CNN’s te verwerken in energiezuinige modes, waarmee nieuwe mogelijkheden ontstaan voor AI in embedded systemen.

Mijn Elektor-collega’s hebben de hardware al beschreven in twee eerdere artikelen [2][3], dus ik zal me in dit artikel concentreren op de software die nodig is om met de MAX78000 aan de slag te gaan. We gaan ook een CNN trainen om wat sleutelwoorden te herkennen en hardware aan te sturen. De MAX78000FTHR-kaart (figuur 1) die ik gebruik is verkrijgbaar in de Elektor Store.
We gaan aantonen dat de spraakherkenning werkt door een spraakbestuurde koffiemachine te bouwen. Nu COVID-19 nog steeds rondwaart zijn apparaten die door iedereen worden gebruikt, zoals de koffieautomaat, potentiële verspreiders van het virus. Wij gaan een koffieautomaat bouwen die iedereen kan bedienen, zonder hem aan te raken. Dat geeft een mooie demonstratie van de software-workflow voor de MAX78000. Met de SDK kunnen we programmeren in C of C++. De documentatie is te vinden in de GitHub repository voor de MAX78000 van Maxim.
Twee verschillende invalshoeken
Voor AI op een embedded apparaat zijn nieuwe vaardigheden nodig. Welke dat zijn, ligt aan uw achtergrond en ervaring. Wie ervaring heeft met neurale netwerken zal erg moeten wennen aan de wereld van embedded software. Maar ook embedded ontwikkelaars die aan AI willen beginnen, kunnen het moeilijk krijgen. Als u wilt gaan werken met vooraf getrainde netwerken, heeft u niet meer nodig dan een gewone ontwikkel-PC.
We willen aandacht besteden aan beide onderwerpen en we willen een begin maken met het trainen van een neuraal netwerk. Om het wat gemakkelijker te maken, gaan we een bestaand voorbeeld aanpassen en niet vanaf nul beginnen. Zo krijgt u een beeld van de gereedschappen die eraan te pas komen.
De embedded software, dus de implementatie op de MAX78000 zelf, doen we als tweede stap. Dat kan lastig zijn, als u geen ervaring hebt met embedded software. Daarom behandelen we de basisbegrippen in twee artikelen. Dit eerste artikel gaat vooral over AI. In het tweede artikel duiken we in het ontwikkelen voor de MAX78000.
Bij voorkeur een CUDA-capable GPU
Als u aan de slag wilt gaan met het zelf maken van neurale netwerken, dan moet u met één ding rekening houden. Om neurale netwerken voor de MAX78000 te trainen, is sterk aan te raden om in uw systeem een NVIDIA-GPU te hebben die CUDA ondersteunt. De GPU’s van AMD en Intel bieden geen ondersteuning voor deep learning met neurale netwerken, zoals Tensor Flow en PyTorch, daar is de Nvidia CUDA echt beter geschikt voor. En ook al hebt u een CUDA-capable GPU van NVIDIA, dan moet die wel een chip met Maxwell-architectuur (NVIDIA GTX 9-serie) of een NVIDIA Tesla K80 hebben.
Ik schrijf dit begin 2021 en nieuwe GPU’s zijn kostbaar, dus u moet overwegen of u die wilt aanschaffen. U kunt zich behelpen door alle berekeningen op uw CPU te doen, maar dat zal de verwerking op zijn minst met een factor 10 vertragen.
Een slimme koffiemachine met een MAX78000
Bij het aanpassen van een koffieautomaat kan iedereen zich wel iets voorstellen, misschien hebt u er zelfs ervaring mee. Populaire aanpassingen zijn bijvoorbeeld inbouwen van een WiFi-interface en nieuwe functies voor het koffiezetten. Of misschien hebt u wel eens een defecte automaat gerepareerd? Onze demo is lang niet perfect, maar hij moet de volgende functies krijgen:
- Hij moet “Happy” herkennen als zijn naam.
- Hij moet vragen of hij koffie moet maken.
- Hij moet vragen of er een beker geplaatst is.
- Hij moet feedback aan de gebruiker geven via een LCD.
De hardware is vrij simpel. We hebben nodig:
- MAX78000FTHR RevA-board (figuur 1)
- Breadboard
- Dupont-kabeltjes
- 2,2” TFT-scherm uit de ElektorShop (figuur 2)

Figuur 2: Het LCD.
Er komt geen koffieautomaat voor op de lijst. Wees gerust: er zijn geen werkende koffiemachines beschadigd bij het doen van dit project. We willen alleen aantonen dat het concept kan werken. Inbouwen in een echte koffieautomaat is per fabrikant verschillend, dus wij gebruiken een virtuele automaat. Daarmee zijn de basisprincipes te demonstreren.
Training en synthese
Maxim biedt een aantal voorbeelden om de Convolutionele Neurale Netwerken te trainen die in hun voorbeelden worden gebruikt. Op hun GitHub-pagina staat een gids met de benodigde software. Ze gaan ervan uit dat u werkt met Linux en dat u een CUDA-compatibele grafische kaart van NVIDIA hebt. Voor de kws20_demo waren een NVIDIA GeForce GTX 1050Ti en een AMD Ryzen 2700X meer dan 3,5 uur aan het rekenen met CUDA-versnelling.
Er zijn wel wat experimentele drivers die met het Windows Subsystem voor Linux werken en toegang bieden tot CUDA, maar het is toch echt aan te raden om te werken met een Debian Linux-variant zoals Ubuntu. We gaan dus uit van een verse installatie van Ubuntu 20.04 en de beschikbare tools van Maxim.
De eerste stap na de installatie van Ubuntu is het installeren van de NVIDIA-drivers om toegang te krijgen tot de CUDA-versneller. Gebruik op Ubuntu Software and Updates en voeg de juiste drivers voor uw kaart toe onder het tabblad Additional Drivers. In figuur 3 ziet u de juiste driver voor de GTX1050Ti.
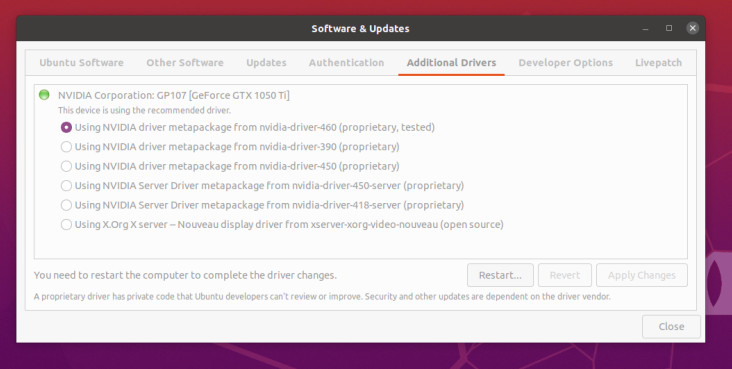
U moet het systeem dan opnieuw opstarten en als uw display na de reboot nog steeds werkt, hebt u de NVIDIA-driver goed geïnstalleerd. U kunt dat ook controleren met het tool nvidia-smi, zoals te zien is in figuur 4. Dat geeft ook de gebruikte CUDA-versie weer (in dit geval 11.2).
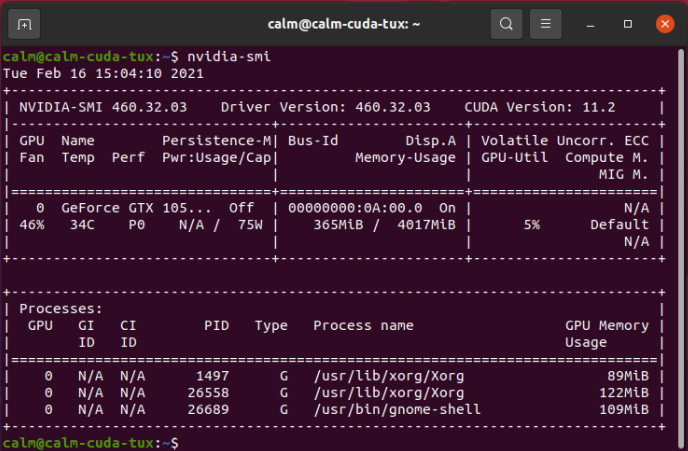
Volg voor het installeren van de software de aanwijzingen die Maxim hier geeft. Aan de hand van het stappenplan voor Linux in de handleiding kunt u een neuraal netwerk gaan trainen op uw PC. Bij de laatste stap voor de embedded software-ontwikkelkit kunt u wat bochten afsnijden. De ARM-compiler kan in Ubuntu worden geïnstalleerd met sudo apt install gcc-arm-none-eabi. U hoeft de ARM-compiler dan niet toe te voegen aan het bestand ~/.profiles. De huidige versie van de RISC V-compiler is, op het moment dat we dit schrijven, is dat versie 10.1. Download die en pak de bestanden uit in uw home-directory. Voeg de volgende regels toe aan uw ~/.profiles:
echo $PATH | grep -q -s "~/xpack-riscv-none-embed-gcc-10.1.0-1.1/bin"
if [ $? -eq 1 ] ; then
PATH=$PATH:~/xpack-riscv-none-embed-gcc-10.1.0-1.1/bin
export PATH
RISCVGCC_DIR=~/xpack-riscv-none-embed-gcc-10.1.0-1.1/
export RISCVGCC_DIR
fi
Nu kunt u netwerken trainen op uw computer. De volgende stap die nodig is, is de synthese. De synthese zet een getraind netwerk om in iets dat de MAX78000 kan gebruiken. De installatiehandleiding voor de synthese staat hier. U hebt het gedeelte voor de training al geïnstalleerd, dus u kunt meteen doorgaan naar het hoofdstuk Upstream Code in de handleiding.
Als u al deze stappen hebt uitgevoerd, kunt u zelf de synthese van modellen doen voor de MAX78000. U kunt dan ook de scripts aanpassen om nieuwe termen te herkennen als die beschikbaar zijn in de getrainde data.
Het voorbeeld voor woordherkenning aanpassen en trainen
Eén van de beschikbare voorbeelden is het herkennen van sleutelwoorden. Zoals al beschreven in het artikel van Clemens Valens, herkent de demo 20 voorgetrainde woorden. De woorden zijn “up, down, left, right, stop, go, yes, no, on, off, one, two, three, four, five, six, seven, eight, nine, zero” en zijn gekozen uit een verzameling van 31 woorden die een gebruiker kan trainen. De complete lijst van ondersteunde woorden is “backward, bed, bird, cat, dog, down, eight, five, follow, forward, four, go, happy, house, learn, left, marvin, nine, no, off, on, one, right, seven, sheila, six, stop, three, tree, two, up, visual, wow, yes, zero”.
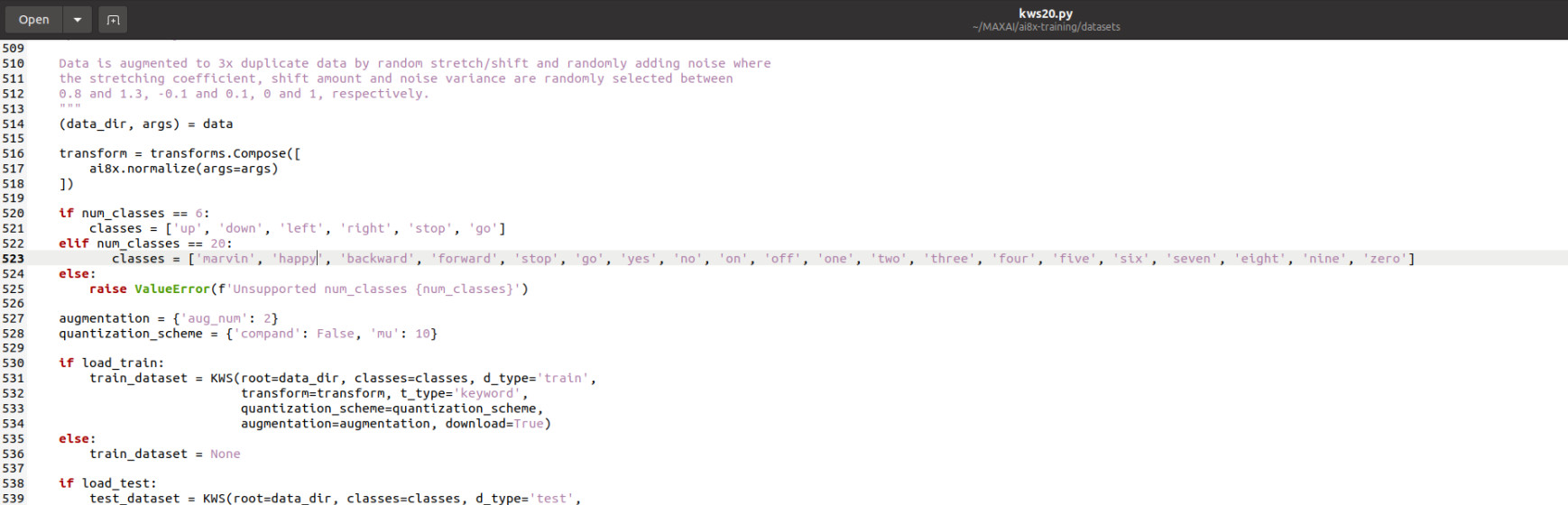
Voor onze demo houden we het bij 20 sleutelwoorden, maar we gebruiken “marvin, happy, backward, forward, stop, go, yes, no, on, off, one, two, three, four, five, six, seven, eight, nine, zero”.
Om de lijst aan te passen, gaan we naar de map ai8x-training op onze Ubuntu-machine (zie figuur 5).
In die map gaan we het bestand ./datasets/kws20.py aanpassen zoals in figuur 6.
We openen dan een terminal en gaan naar de map ai8x-training. Om het CNN met de nieuwe sleutelwoorden te krijgen, starten we de training met ./scripts/train_kws20_v3.sh.
Dan begint het trainen en dat kan een paar uur, of een paar dagen kosten, afhankelijk van de hardware. Als het trainen klaar is, vindt u in ./logs/ een nieuwe map met als naam de tijd en de datum met daarin uw trainingsresultaten. Die moeten dan gesynthetiseerd worden om ze met de MAX78000 te kunnen gebruiken.
Synthese van de data
Na het trainen moet de data in een vorm worden gebracht die de MAX78000 kan laden. We moeten naar de map ai8x-synthesis om bestanden te verplaatsen en verwijderen. Verwijder de inhoud van de map trained om te voorkomen dat er met oude data wordt gewerkt. Kopieer van de map ai8x-training/logs/{starttijd}/ het bestand best-pth.tar naar ai8x-synthesis/trained/. We hebben beide bestanden nodig voor de verdere verwerking. Start een terminal en ga naar de map ai8x-synthesis.
Draai source bin/activate om de Python-omgeving op te zetten. We kunnen nu een kwantisatie doen van ons gekopieerde getrainde met ./quantize.py trained/best.pth.tar trained/ai85-kws20-v3-qat8-q.pth.tar –device MAX78000 -v. Het resultaat is een gekwantiseerde file met de naam ai85-kws20-v3-qat8-q.pth.tar in de map trained. Na het kwantiseren kunnen we wat code genereren plus de definitieve bestanden die de MAX78000 kan gebruiken.
De laatste stap is het genereren van code om later te gebruiken. Typ in hetzelfde terminalvenster ./ai8xize.py --verbose --log --test-dir ~/MAX78000/ --prefix kws20_v3 --checkpoint-file trained/ai85-kws20_v3-qat8-q.pth.tar --config-file networks/kws20-v3-hwc.yaml --softmax --device MAX78000 --compact-data --mexpress --timer 0 --display-checkpoint --board-name FTHR_RevA
Dat genereert een map MAX78000 in uw home-directory, met daarin een kleine toepassing die zichzelf test met voorgedefinieerde testdata in de code. Die toepassing staat in een map kws20_v3, in de vorm van de files weights.h, cnn.h en cnn.c, en bevat het CNN en de beschikbare functies. Op dat punt begint de embedded ontwikkeling, want we hebben nu een CNN dat kan luisteren naar onze aangepaste sleutelwoorden.
Meer lezen
Wilt u een volgende stap maken in de wereld van de CNN’s? Begin dan met deze introductie. Als u dit tutorial volgt, gaat u meer begrijpen van wat de scripts en het trainen onder water allemaal doen. Op [12] vindt u wat uitleg over de wiskunde achter het CNN en waarom we die gebruiken. Dit zal het gemakkelijker voor u maken om in dit veld aan de slag te gaan.
De tools van Maxim werken met PyTorch en TensorFlow, die alleen volledige ondersteuning bieden voor CUDA op GPU’s van NVIDIA. Maar als u niet bang bent uitgevallen, kunt u ook kijken naar ROCm van AMD. Dat is een aangepaste versie van PyTorch, die kan werken met bepaalde GPU’s van AMD. Er zijn ook mogelijkheden geïntegreerd in sommige CPU’s van AMD, maar dat is experimenteel en wordt officieel niet ondersteund.
Hoe gaan we dit gebruiken met de MAX78000?
Nu we nieuwe CNN’s voor de MAX78000 kunnen trainen, is het tijd om verder te gaan met de embedded software. We gaan voor het ontwikkelen gebruik maken van de tool die Maxim daarvoor beschikbaar stelt. De Eclipse-IDE is te downloaden van Maxim’s website. De tools werkten bij mij ook heel goed in een virtuele machine. Dat is handig, want als er iets misgaat met mijn ontwikkelsysteem, kan ik gemakkelijk overschakelen naar een andere virtuele machine. Bovendien is het daardoor mogelijk om snapshots te maken van de ontwikkelomgeving. We gaan de code voor onze koffiemachine voorlopig schrijven in C. U kunt intussen alvast kijken in de MAX78000-documentatie en de handleiding voor de MAX78000. Er wordt nog aan deze documentatie gewerkt, dus als u iets mist, kunt u daar een GitHub-issue over maken, of het melden via www.elektormagazine.com/labs/MAX78000.
Vragen of opmerkingen?
Als u technische vragen of opmerkingen hebt over dit artikel, stuur dan een email naar de auteur via mathias.claussen@elektor.com of neem contact op met Elektor via editor@elektor.com.
Bent u klaar om innovatieve kunstmatige intelligentie (AI) oplossingen te ontwikkelen?
Doe mee aan de MAX78000 AI Design Contest. Integreer de MAX78000 in een creatief ontwerp en maak kans op een mooi geldbedrag! Registreer nu alvast voor een gratis MAX78000FTHR Eval Kit. Deel uw projectvoorstel met ons en wie weet, kunt u al heel snel aan de slag!

Discussie (0 opmerking(en))