
Nieuwe cachehiërarchie verbetert prestaties en vermindert energieverbruik
16 juli 2017
op
op
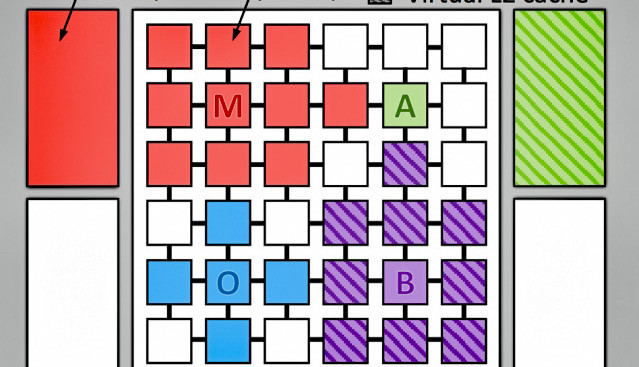
Onderzoekers van de Computer Science and Artificial Intelligence Laboratory bij het MIT zijn erin geslaagd een nieuwe ad hoc cache-indeling te ontwikkelen, die bij voor de rest gelijke hardware de rekenkracht met maximaal 30 % doet toenemen en het energieverbruik tot wel 85 % doet afnemen.
Al decennialang wordt de rekenkracht van processors vergroot door het gebruik van zogenaamd cachegeheugen, waarmee het verschil tussen het relatief langzame RAM van het werkgeheugen en de hoge klokfrequentie van de processor wordt opgevangen. Een cache is een klein, meestal op de chip geïntegreerd geheugen met een zeer hoge werksnelheid, waar de rekenkernen bijna zonder vertraging mee kunnen werken. CPU’s voor PC’s en laptops hebben zelfs een kleine 1st-level en een iets grotere 2nd-level cache. De Pentium 4 bijvoorbeeld had twee L1-caches van elk 8 kB en een voorgeschakelde L2-cache van 256 kB. Een moderne i7 heeft per rekenkern al een L1-cache van 32 kB, gescheiden voor instructies en data, en een extra L2-cache van 256 kB met dezelfde kloksnelheid als de processor plus een voor alle cores gezamenlijke, iets langzamere L3-cache van maximaal 20 MB. Om de rekenkracht verder te vergroten, onafhankelijk van de klokfrequentie, worden dus extreme maatregelen genomen, die veel ruimte innemen op de chip en dus kostbaar zijn en het energieverbruik opdrijven. Denk u eens in: iets meer dan 20 jaar geleden had een normale PC minder RAM -geheugen ter beschikking dan er nu aan L3-cache in een CPU zit!
De onderzoekers van de MIT hebben nu gezocht naar alternatieve strategieën voor versnelling. De hardware voor de experimenten was een Jenga-systeem met een 36-core-CPU met een configureerbare L3-cache met de enorme grootte van 1 GB. De L1- en L2-caches waren zoals gebruikelijk vast toegewezen aan de individuele kernen. Het belangrijke verschil is dat de L3-cache ad hoc, d.w.z. tijdens het uitvoeren van de code, naar behoefte kan worden aangepast. Daarbij krijgt dan een thread die net bezig is met een groot array van bijvoorbeeld 32 MB niet slechts 1/36 van de L3-cache, maar zoveel als hij op dat moment nodig heeft. Het onnodig verwerken van de data in twee of meer stappen en heen-en-weer schuiven van data bij een vaste toewijzing wordt zo vermeden. Het resultaat is niet alleen een 20 tot 30 % snellere verwerking van de code, maar ook een energiebesparing van 20 tot 85 %, omdat er duidelijk minder onnodige interne bewerkingen worden uitgevoerd.
De exacte werkwijze is te lezen in dit paper in PDF-formaat.
Versnellen
Al decennialang wordt de rekenkracht van processors vergroot door het gebruik van zogenaamd cachegeheugen, waarmee het verschil tussen het relatief langzame RAM van het werkgeheugen en de hoge klokfrequentie van de processor wordt opgevangen. Een cache is een klein, meestal op de chip geïntegreerd geheugen met een zeer hoge werksnelheid, waar de rekenkernen bijna zonder vertraging mee kunnen werken. CPU’s voor PC’s en laptops hebben zelfs een kleine 1st-level en een iets grotere 2nd-level cache. De Pentium 4 bijvoorbeeld had twee L1-caches van elk 8 kB en een voorgeschakelde L2-cache van 256 kB. Een moderne i7 heeft per rekenkern al een L1-cache van 32 kB, gescheiden voor instructies en data, en een extra L2-cache van 256 kB met dezelfde kloksnelheid als de processor plus een voor alle cores gezamenlijke, iets langzamere L3-cache van maximaal 20 MB. Om de rekenkracht verder te vergroten, onafhankelijk van de klokfrequentie, worden dus extreme maatregelen genomen, die veel ruimte innemen op de chip en dus kostbaar zijn en het energieverbruik opdrijven. Denk u eens in: iets meer dan 20 jaar geleden had een normale PC minder RAM -geheugen ter beschikking dan er nu aan L3-cache in een CPU zit!
Alternatieven
De onderzoekers van de MIT hebben nu gezocht naar alternatieve strategieën voor versnelling. De hardware voor de experimenten was een Jenga-systeem met een 36-core-CPU met een configureerbare L3-cache met de enorme grootte van 1 GB. De L1- en L2-caches waren zoals gebruikelijk vast toegewezen aan de individuele kernen. Het belangrijke verschil is dat de L3-cache ad hoc, d.w.z. tijdens het uitvoeren van de code, naar behoefte kan worden aangepast. Daarbij krijgt dan een thread die net bezig is met een groot array van bijvoorbeeld 32 MB niet slechts 1/36 van de L3-cache, maar zoveel als hij op dat moment nodig heeft. Het onnodig verwerken van de data in twee of meer stappen en heen-en-weer schuiven van data bij een vaste toewijzing wordt zo vermeden. Het resultaat is niet alleen een 20 tot 30 % snellere verwerking van de code, maar ook een energiebesparing van 20 tot 85 %, omdat er duidelijk minder onnodige interne bewerkingen worden uitgevoerd.
De exacte werkwijze is te lezen in dit paper in PDF-formaat.
Read full article
Hide full article
Discussie (0 opmerking(en))